Online usage of Springer Nature documents
SDG-related content that is published under a Gold OA model has significantly more downloads.
36,823 Springer Nature documents were published in 2017 and are related to at least one SDG. On average, these documents were downloaded 1,437 times since with a median of 730.
We clustered all documents with regards to their access status in four different segments (Table 2):
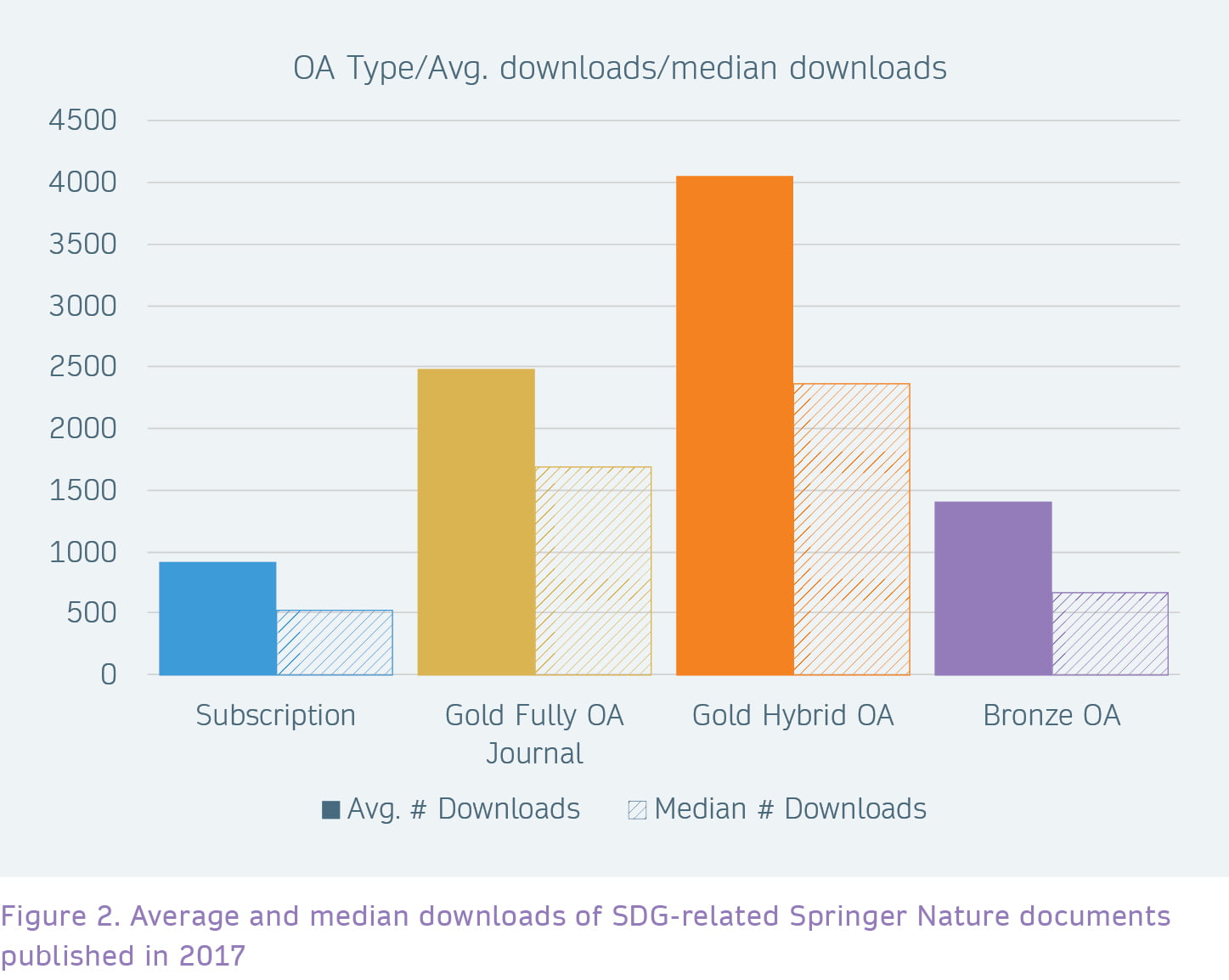
We can see a clear OA advantage in the data. For example, documents published Gold Hybrid OA have the highest average and median number of downloads, 4,049 and 2,368 respectively. Second come Gold Fully OA documents with an average of 2,489 and a median of 1,699 downloads. This compares to an average of 923 and a median of 522 downloads for Subscription documents. So Gold OA Hybrid documents have 4.4 times as many downloads as Subscription documents, and Fully Gold OA publications have 2.7 times as many.
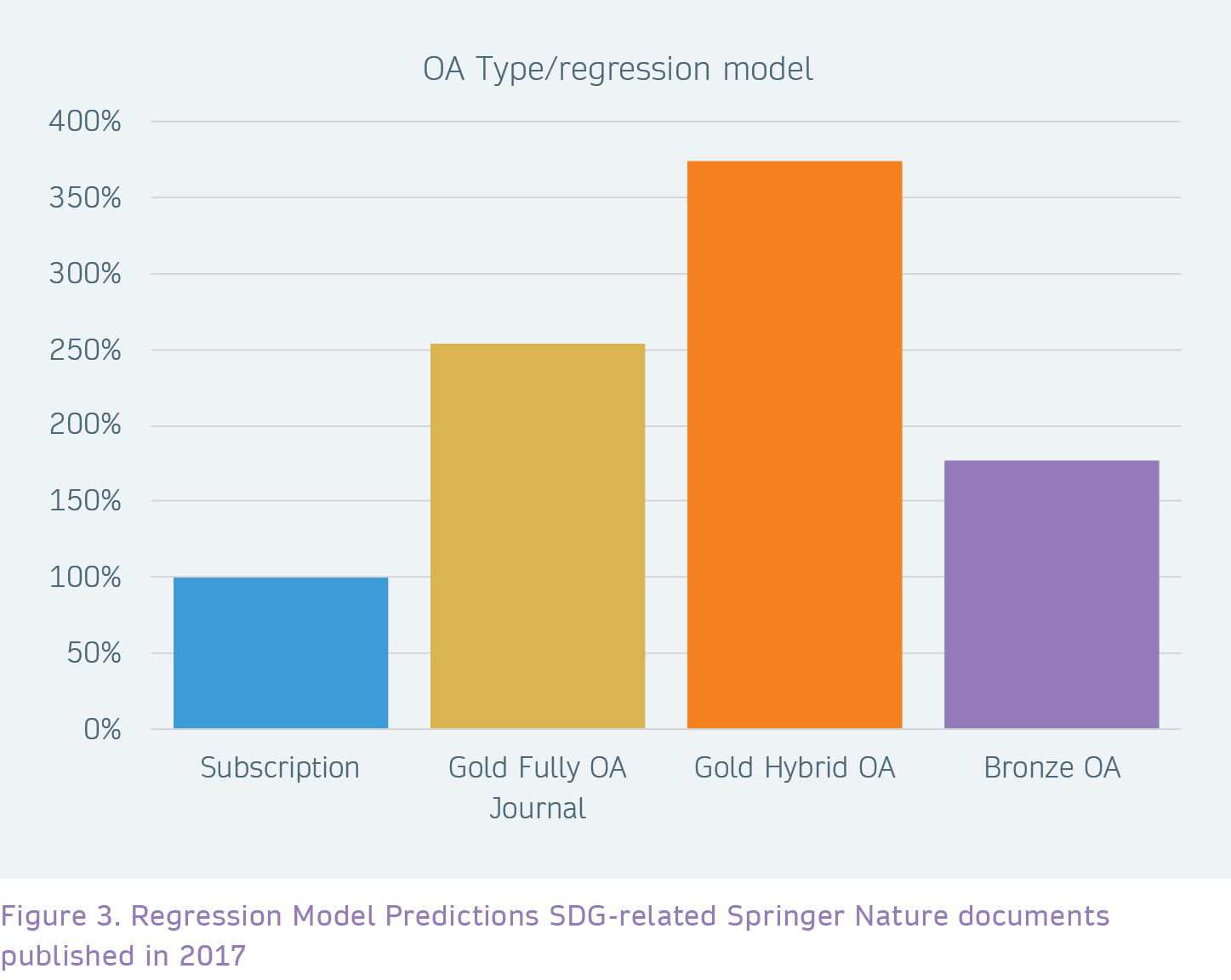
After controlling for several variables on a document, author and journal level, our regression model predicts similar numbers. According to the model, Gold Hybrid OA SDG-related documents on average have a download rate that is 3.7 times higher than Subscription documents; documents in Fully Gold OA publications have a rate that is 2.5 times higher.
The variation noted between Hybrid OA and Fully OA is worthy of note. Several factors could potentially be at play, including the fact that Hybrid journals are more established and therefore attract more users. Although we used the Journal Impact Factor as a proxy for journal prestige in our regression model to control for journal reputation, this metric certainly has its limitations.
Altmetric attention data
OA content is shared more often and gets more attention than Subscription content.
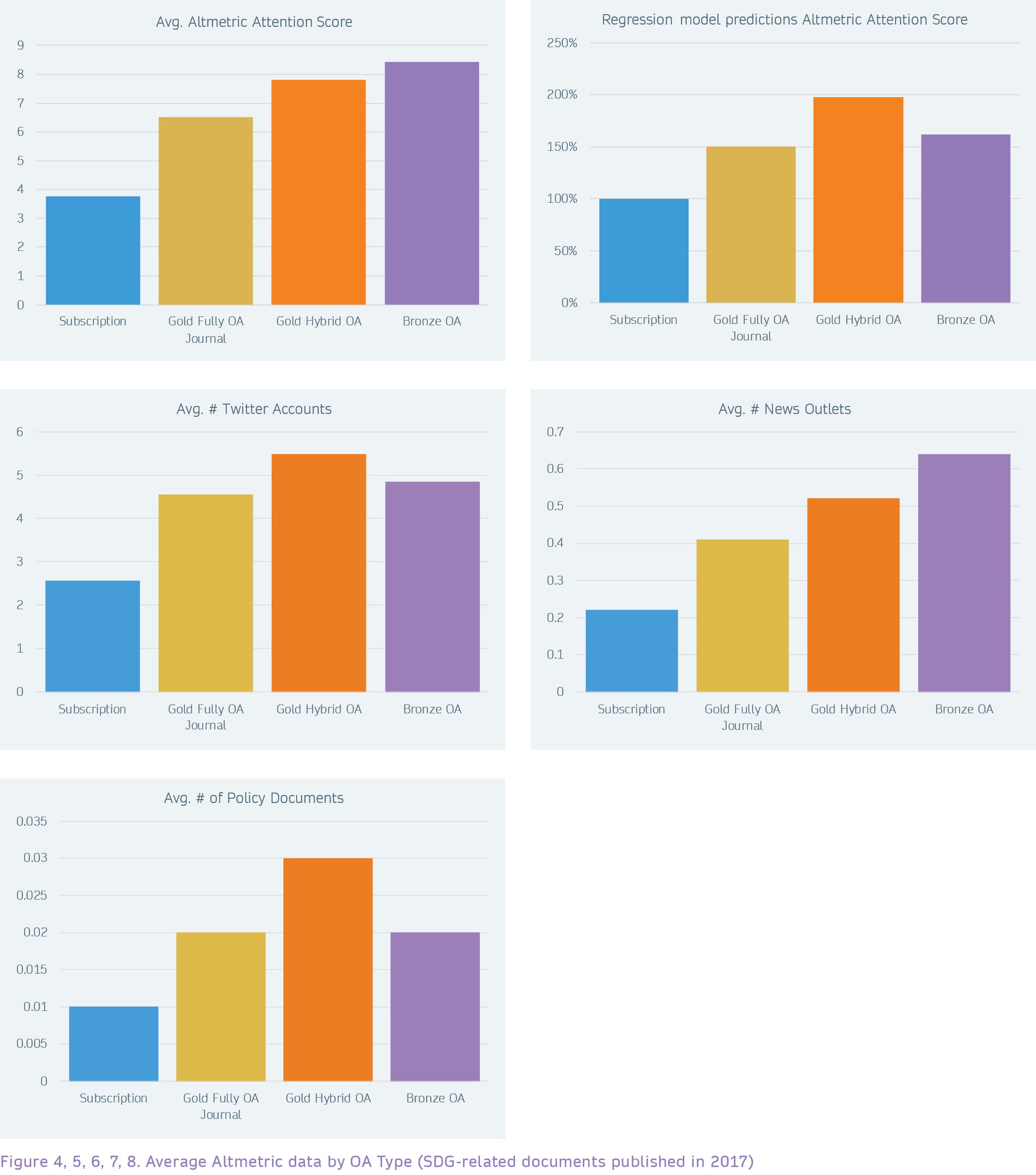
358,293 SDG-related documents from the Dimensions database were analysed, all published in 2017. The vast majority (71%) of them don’t yet have an Altmetric Attention Score, which is a weighted count of all of the online attention for an individual research output, meaning that no activity about them has been found by the provider of this score, Altmetric, in the sources they cover. However, a few documents get a lot of attention, which results in an average Altmetric Attention Score of 5.15 (the highest Altmetric Attention Score in the sample is 7,514). Looking deeper into the various sources that contribute to the Altmetric Attention Score, we see an average number of Twitter accounts tweeting about a document of 3.41, an average number of news outlets writing about content of 0.33, and an average number of policy documents mentioning content of 0.02. It is also important to consider that the Altmetric Attention Score differs significantly by the country of the author(s), since there is a regional bias with regards to the sources covered (e.g. the uptake in usage of Twitter is very different in different countries).
Despite these limitations, we can again see an OA advantage. For Gold OA SDG-related content, the average Altmetric Attention Score, as well as the average number of Twitter accounts, news outlets and policy documents are all higher than the Subscription scores. For example, Gold Hybrid OA documents have a 2.1 times higher average Altmetric Attention Score than Subscription documents, documents in Fully Gold OA publications are 1.7 times higher. The regression model predicts similar numbers: an Altmetric Attention Score that is 2.0 times higher for Gold Hybrid OA documents, and 1.5 times higher for documents in Fully Gold OA publications.
Citation data
There is not a clear OA citation advantage for this cohort of documents.
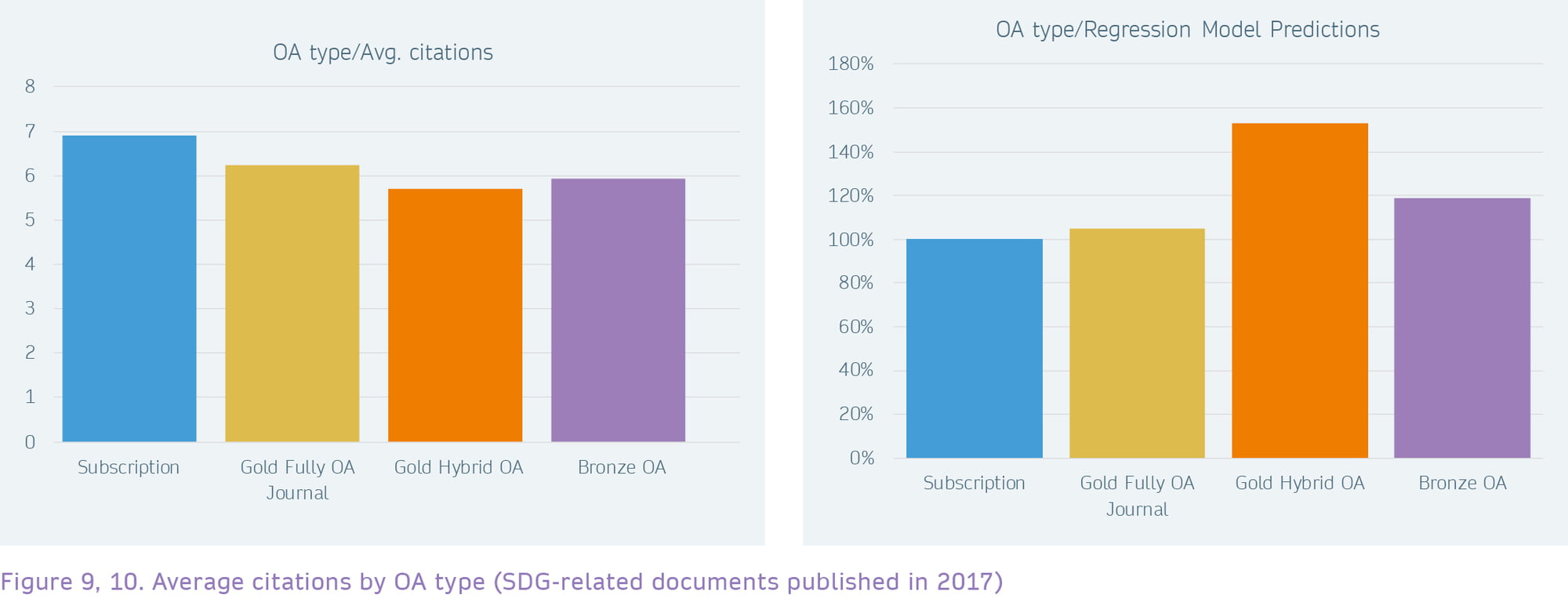
Like Altmetric data, citation data is heavily skewed. 36% of the documents in this sample (SDG-related content published in 2017) have not received a citation yet; the median number of citations is just 2. However, since there are again a few documents that perform particularly well by this metric, the average is 6.57.
Unlike the usage and Altmetric data, we can see only less distinct differences between Subscription, Gold Hybrid OA and Fully Gold OA documents. When controlled for other factors, however, the regression model suggests a citation advantage 1.5 times higher for Gold Hybrid OA documents and 1.1 times for documents in Fully Gold OA publications.
For comparison, the previously mentioned Springer Nature study found that Gold OA documents in Hybrid journals attract 1.4 times more citations when controlled for various author and journal characteristics, so this analysis finds a similar result for Gold Hybrid OA across all publishers.
A case study of Netherlands SDG content
Netherlands research outstrips the global average number of downloads, with a high share of OA documents published.
When we look at documents with at least one Dutch author, we have a sample of 1,061 Springer Nature documents that were published in 2017 and are related to at least one SDG. So far, these documents have had an average of 3,046 and a median of 1,584 downloads. These numbers are well above the global averages of 1,437 and 730 average and median downloads respectively, so more than twice as high. A key reason for this is the fact that the share of OA content amongst Dutch content in Springer Nature publications is substantially higher than the global average, and the previously shown OA advantage.
When we compare the usage data by OA status, we see similar patterns compared to the global study (Table 3):
This analysis has shown that OA content has substantially higher online usage and attention than content that is only available under a Subscription model, both on a global basis and for content with at least one Dutch author. We wanted to investigate whether we can see signs that OA benefits user groups outside of the core academic readership. What we can see from the available data is a much stronger online usage and attention advantage from OA, compared with the observed citation advantage. This would support the assumption that one of the main advantages of OA is that it reaches a number of user groups outside of academia that typically don’t have access to a large amount of Subscription content (since citations are mainly an indicator for academic utilisation). In part two, our online user survey will look deeper at this question, exploring who those non-academic users are and for what purposes they use academic/scholarly content.
Segmentation
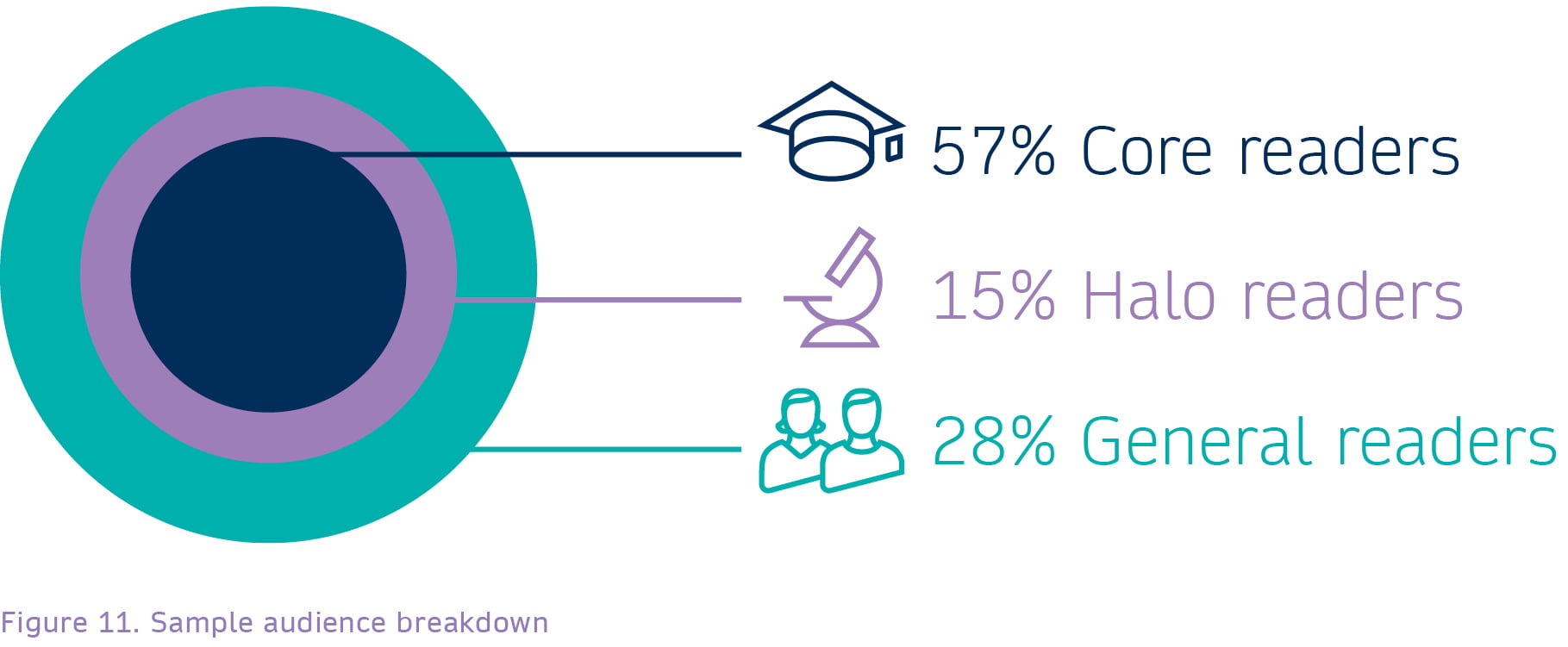
More than 40% of respondents were non-academic users.
The survey asked its 5,994 respondents for information about the organisation they worked or studied at, and their role. Depending on their answers, they were then asked for more detail, such as what industry they worked in if they were a corporate user, or whether they had an academic background if they were retired. The overall audience was segmented based on category, grouping the type of organisation they worked in together with their stated role or job title. This grouping was then split into three segments, based on the degree to which primary research is a major driver for their work:
This top-level split is necessarily somewhat blurred, and arguments could be made for many individuals being re-categorised if they were close to a boundary. The survey gathered only very limited data about each respondent, but it was sufficient to provide distinction for further analysis on their use of content.
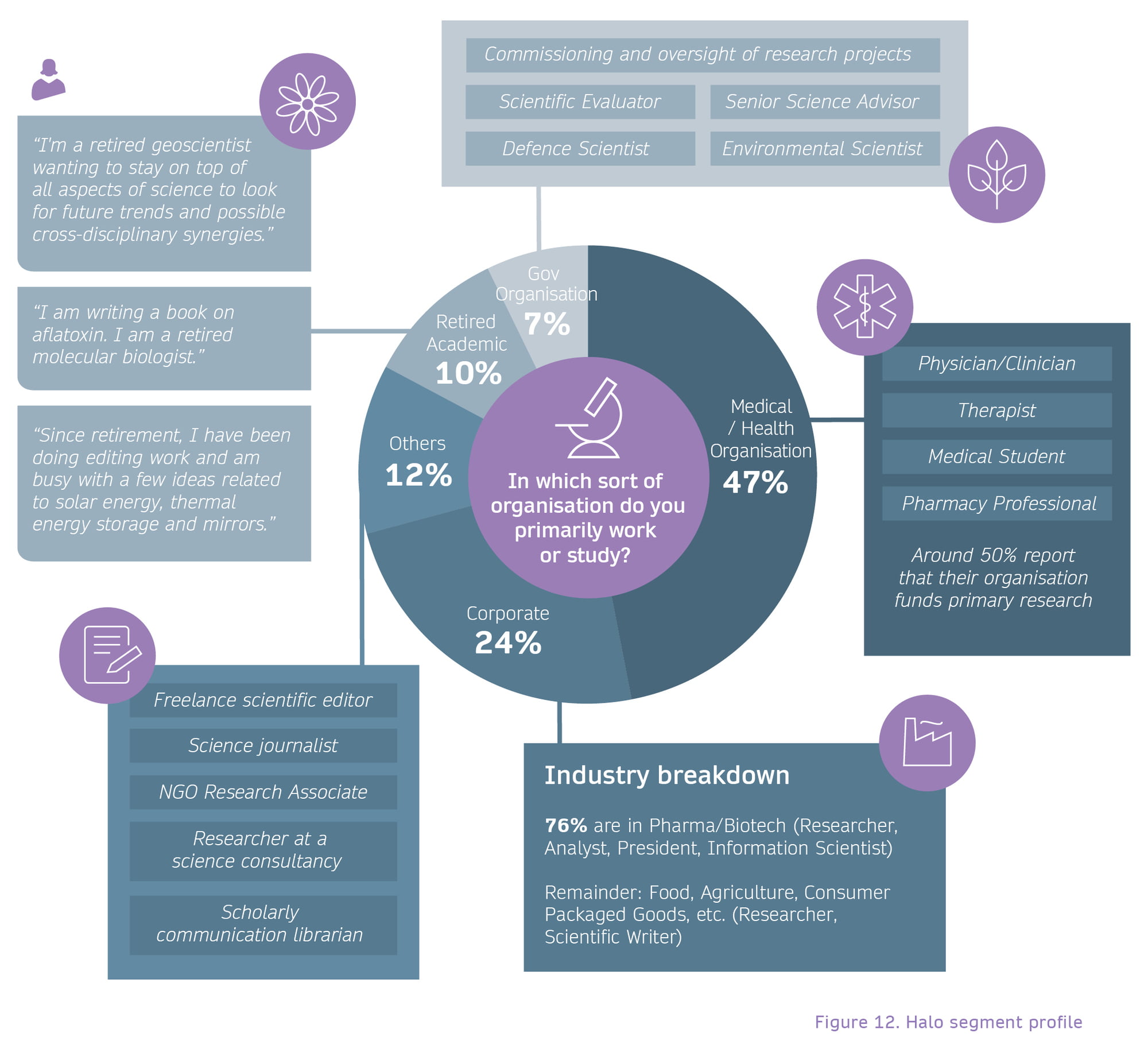
The Halo segment
The Halo segment covers those in industries or roles where a significant proportion are likely to read research for professional purposes, but where the primary part of their role is not conducting and publishing research.
The segment is dominated by those working in hospitals and medical practices, and in pharma/biotech. Other Halo groups include retired academics, who may potentially still have some advisory or influencing role, as well as members of government organisations and a long list of additional job roles (e.g. journalists, librarians or freelance editors).
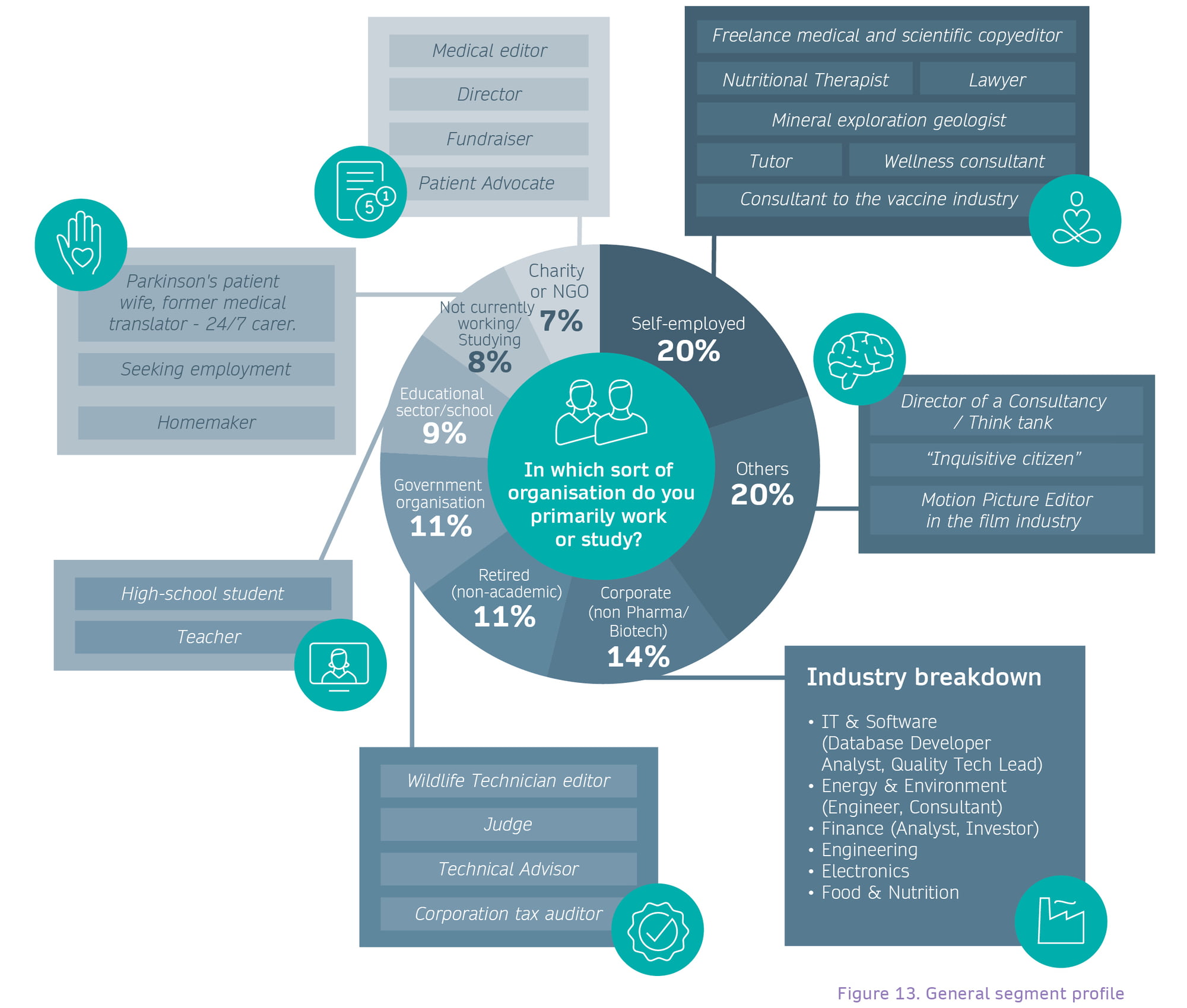
The General segment
The General segment comprises a very ‘long-tail’ of a wide variety of roles, which could be grouped and structured in multiple ways, and accounts for an astonishing 28% of respondents. As well as a wide variety of self-employed roles, there is a large group of corporate employees who are using research but who do not have research roles per se. They come from a wide range of industries and company sizes, including a substantial share of Small and Medium-Sized Enterprises (SMEs). Beyond that there is a broad swathe of roles, from teachers to homeworkers, and to carers and miscellaneous others.
Note that when an organisation type appears in both the Halo and General segments, such as Government organisation, this is because the categorisation has been carried out at organisational and job role level. In the Halo segment these individuals are likely to be carrying out researcher roles; in the General segment they will not (but may work at the same organisation).
Access to research documents
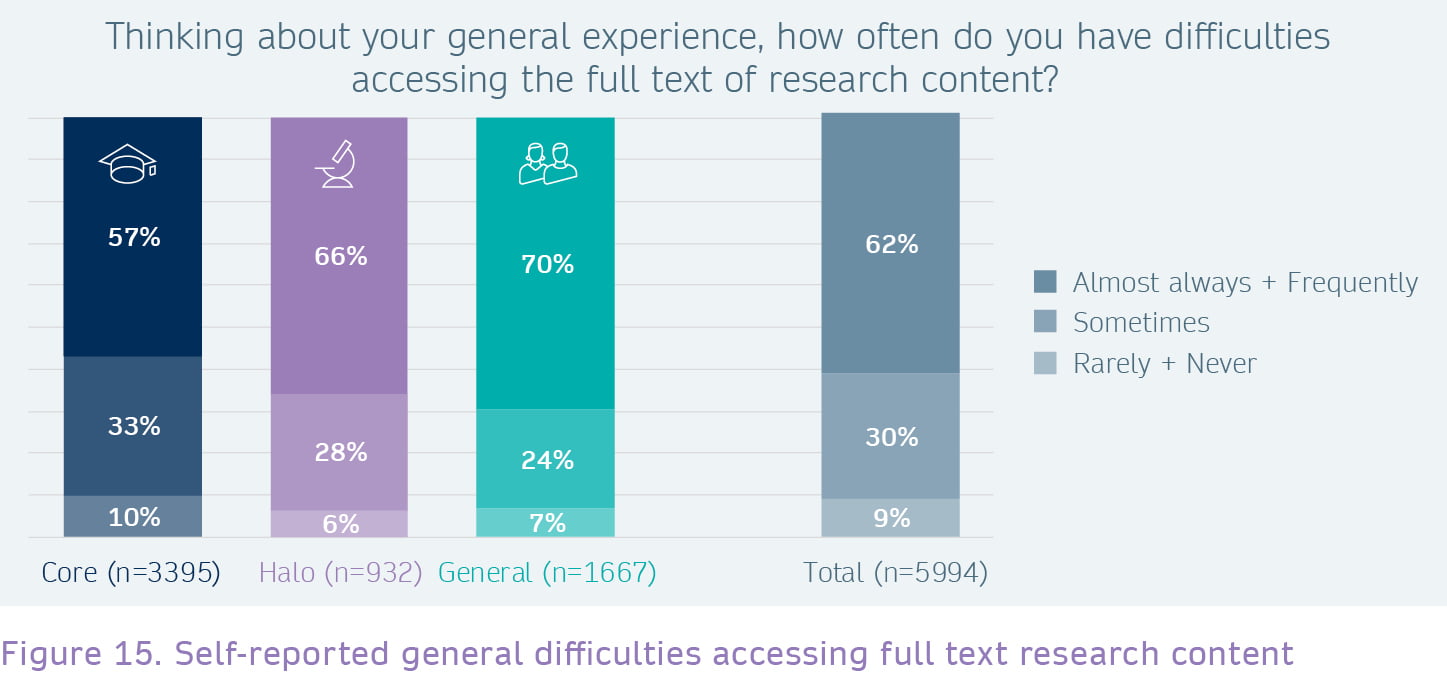
Over 60% of the Halo and General segments find it difficult to access the full text of Subscription documents.
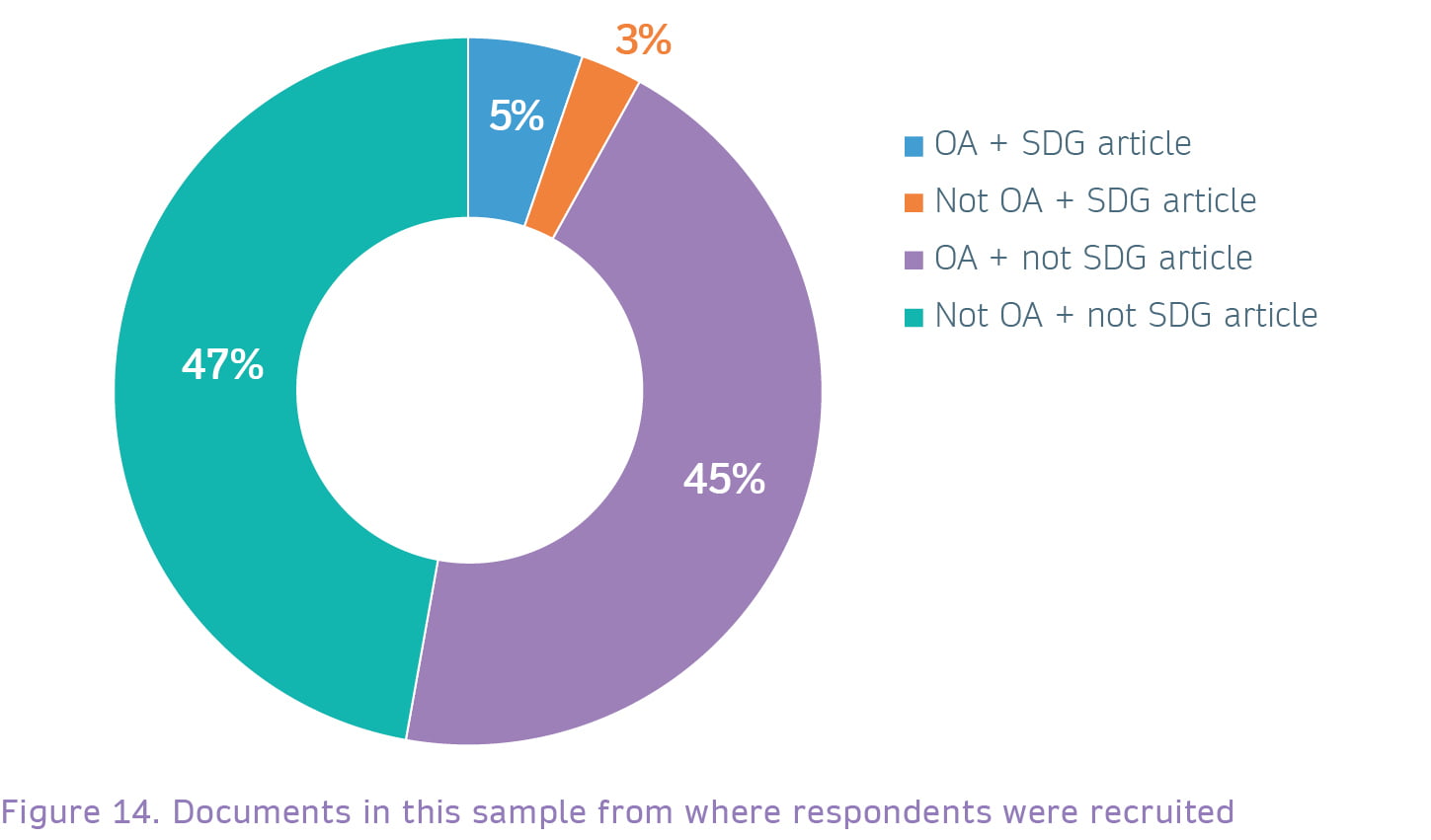
As mentioned in the Methodology section, respondents to this survey were recruited on document pages on nature.com, link.springer.com and biomedcentral.com. Those documents can be clustered in two different ways:
For about half of the users, access to the full text of the documents was not an issue, since they were OA. What about the Subscription documents? Here we can see roughly a 50/50% split between respondents who said they were able to access the full text and those who could not. However, we can see significant differences between the three user segments. While over 60% of the Halo and General segments respectively said that they didn’t have access to the full text, the percentage is much lower for the Core segment. All users from institution types other than University/College and Research Institute reported much higher rates of ‘non-access’. The highest rates were seen from users categorised as Charity/NGO (69%), Self-Employed (68%), Corporate (64%), and non-academic educational sector (61%).
In the survey, we also asked respondents about their general experience, and how often they have difficulties accessing the full text of research content. In total, 62% of respondents said that they often (“almost always” or “frequently”) have difficulties in accessing the full text. Again, the percentage is higher for the Halo (66%) and General (70%) segments. Even so, 57% of the Core audience felt like they often have issues accessing data, particularly when outside of their institution.
Self-reported access difficulties were significantly more common for readers in: Charity/NGO (83%), Corporate (72%), Self-Employed (68%), Medical/health organisations (67%), government organisations (67%), and the non-academic educational sector (66%).
We also asked an open-ended question about how the respondents would try to access the full text if the publication was not open to them (Figure 16). Typical routes for users include contacting an institution’s library or information centre, trying to get institutional access when off-campus via IP-enabled or federated access, asking a colleague or the authors, searching for alternative versions on Google or Google Scholar, or just giving up. Very often users said that they would consider a set of alternative routes that they would apply in sequence, often depending on the relevance of the document in question.
We find many similarities in approaches between the three user segments. However, some significant differences can be observed.
It is worth noting that this survey was running during May, June and July 2020, during what for many countries around the world was a time of lockdown and concern about the unfolding COVID-19 pandemic, forcing many users to work from home and access content remotely. In March, at the start of the pandemic, many institutions had not set up remote access, resulting in widespread access troubleshooting.
During this period, Springer Nature registered a drop in the number of authenticated users by nearly 50% (year-on-year). Further, COUNTER downloads had decreased by 15% (year-on-year). Institutions and publishers moved swiftly to support users and operationalise remote access, and by early April, the situation stabilised. In July, usage on SpringerLink increased by approx. 20% compared to the same period in 2019, both from researchers and a general readership. As the survey was carried out from May-July 2020, it is unlikely that any encountered access issues during this period were due to the absence of remote access set up.
Motivations for reading research documents
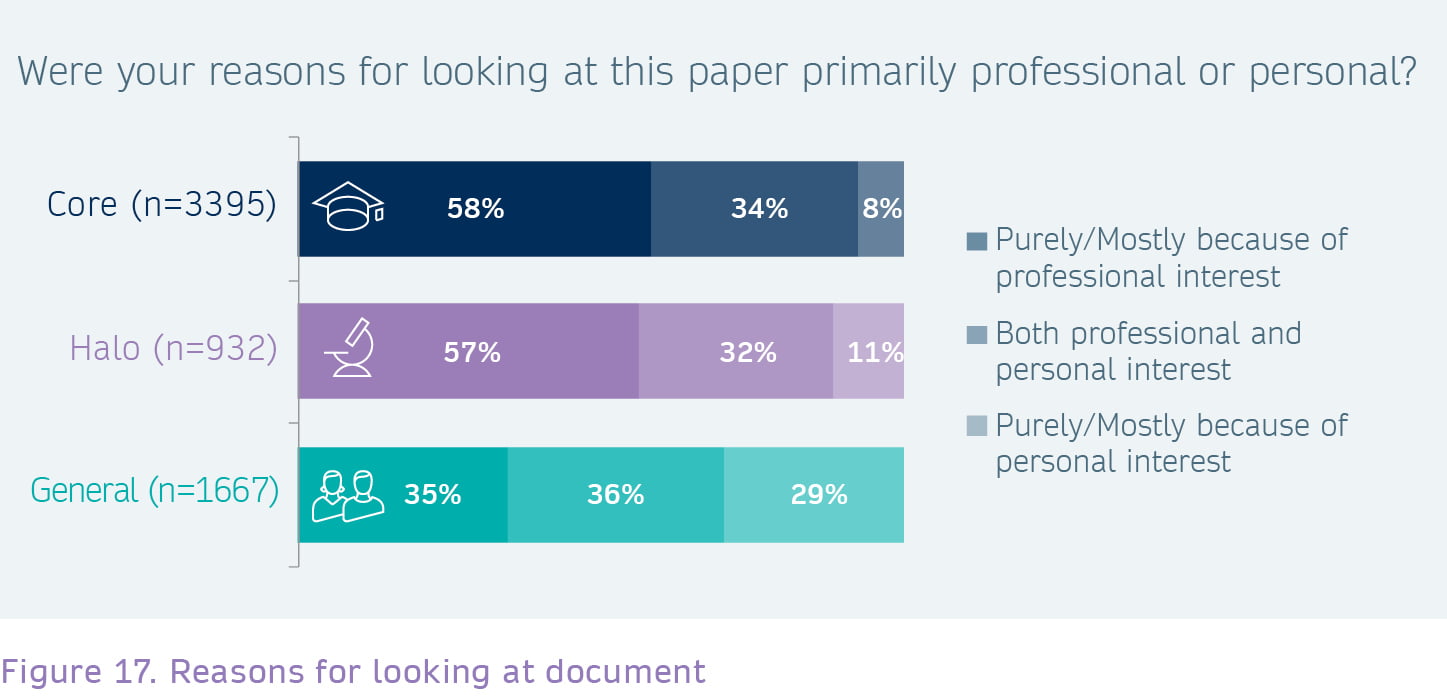
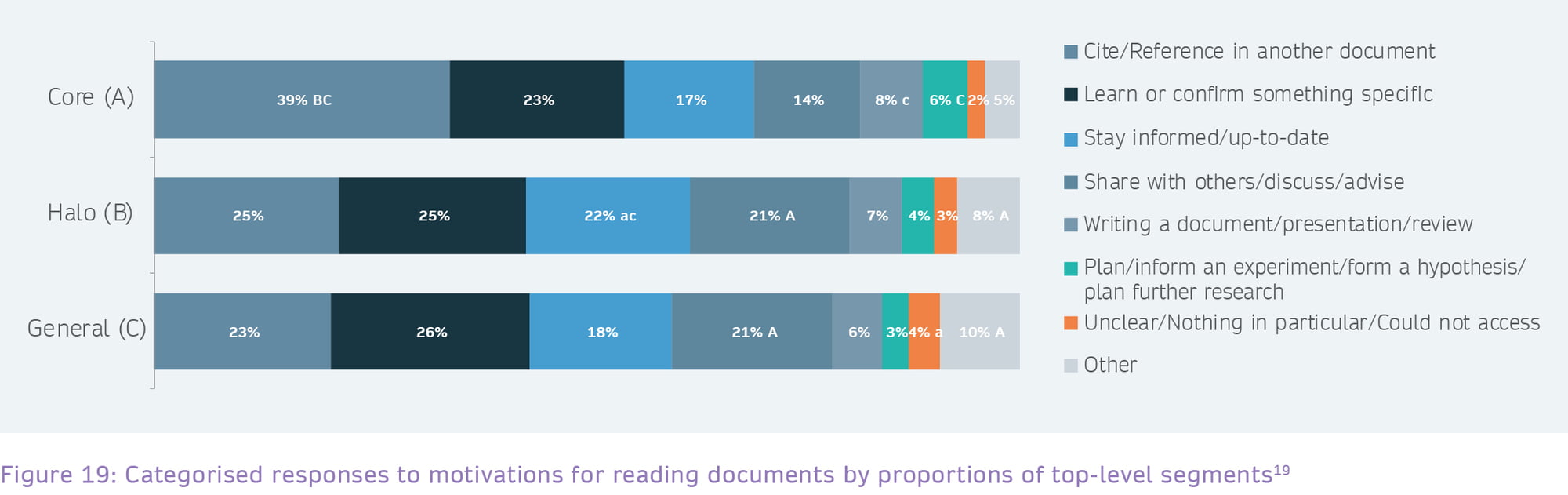
Core users are most likely to cite, where Halo and General readers are looking to learn or to stay up to date.
The survey also asked users for what purposes they use research content, and what the underlying motivations were to start their discovery journey. One question asked about whether their interest in the content was triggered by professional or personal reasons. Interestingly, within the General segment, usage was much more likely to be for personal reasons, or a mixture of both professional and personal interest. But even within the Core and Halo groups roughly a third said that both professional and personal interest motivated them to search for research content. As we can see later in this report, a common use case for users is to stay informed or learn or understand something specific, both of which indeed can have a personal angle to it, e.g. advancing personal knowledge on a general or specific topic.
The survey also asked participants an open text question, to try to capture some detail and richness in usage scenarios: “What have you done, or what do you plan to do, with the information from the research document? It would also be useful to understand your aims in doing so.” To encourage a useful volume of answers, the question also provided some examples:
Understandably, this skewed the answers towards the kind of answers shown in the examples, but these were in any case expected to have been the most common answers. There were 5,760 responses to this question, and analysis and grouping of the open text responses is shown in Figure 18.
It should be remembered that the method of asking the question using an open text response does mean that the answers are necessarily non-exclusive. In other words, just because a respondent answered that they were using the document to plan an experiment does not mean that they would not also have planned to share the document. Most respondents would likely be trying to be brief, and so would be very unlikely to list all of their motivations. We should therefore perhaps interpret the answers as being the intention that was most ‘top of mind’ when answering.
Furthermore, there were at least two ways for respondents to interpret the question: either as “what were you doing with this document” or “why this document?”. The two questions are not as distinct as they first sound, and the answers often cover both. But this question is only an attempt to explore the broad topic, not an attempt to tightly define the varieties of motivation and behaviour in reading research documents, much of which has been researched previously.
Some of the answers shown here demonstrate the use of the research literature for diagnosis and to answer other medical questions – again a reflection of the timing of our research during the pandemic. A pertinent question arising is what publishers and other parts of the research ecosystem can and should do to better enable the use of the research literature by non-specialists.
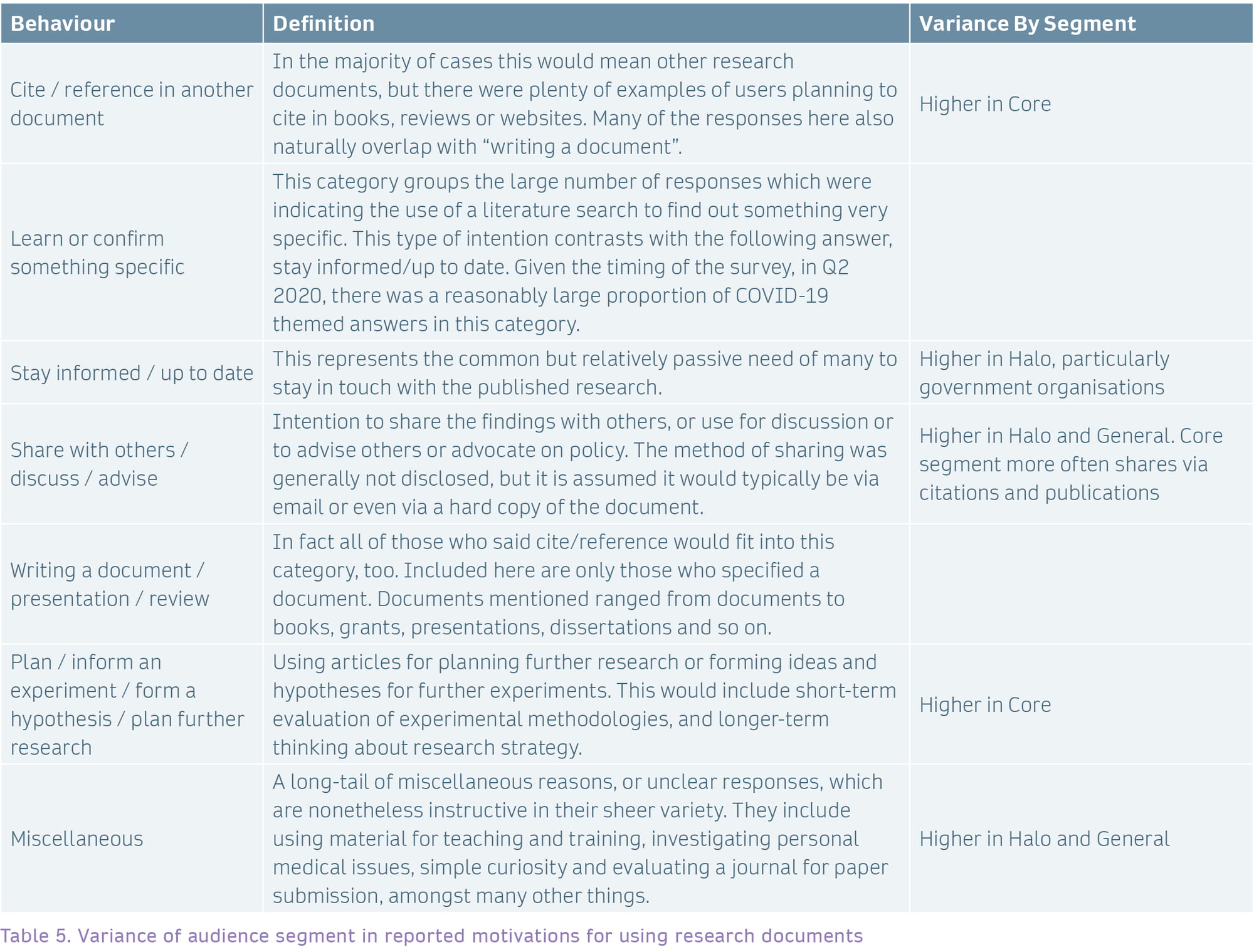
Variance of audience segment in reported motivations
Figure 19: Letters signify where there are statistically significant differences between groups, with a,b,c indicating a difference at p<=0.05 and A,B,C indicating a difference at p<=0.001.
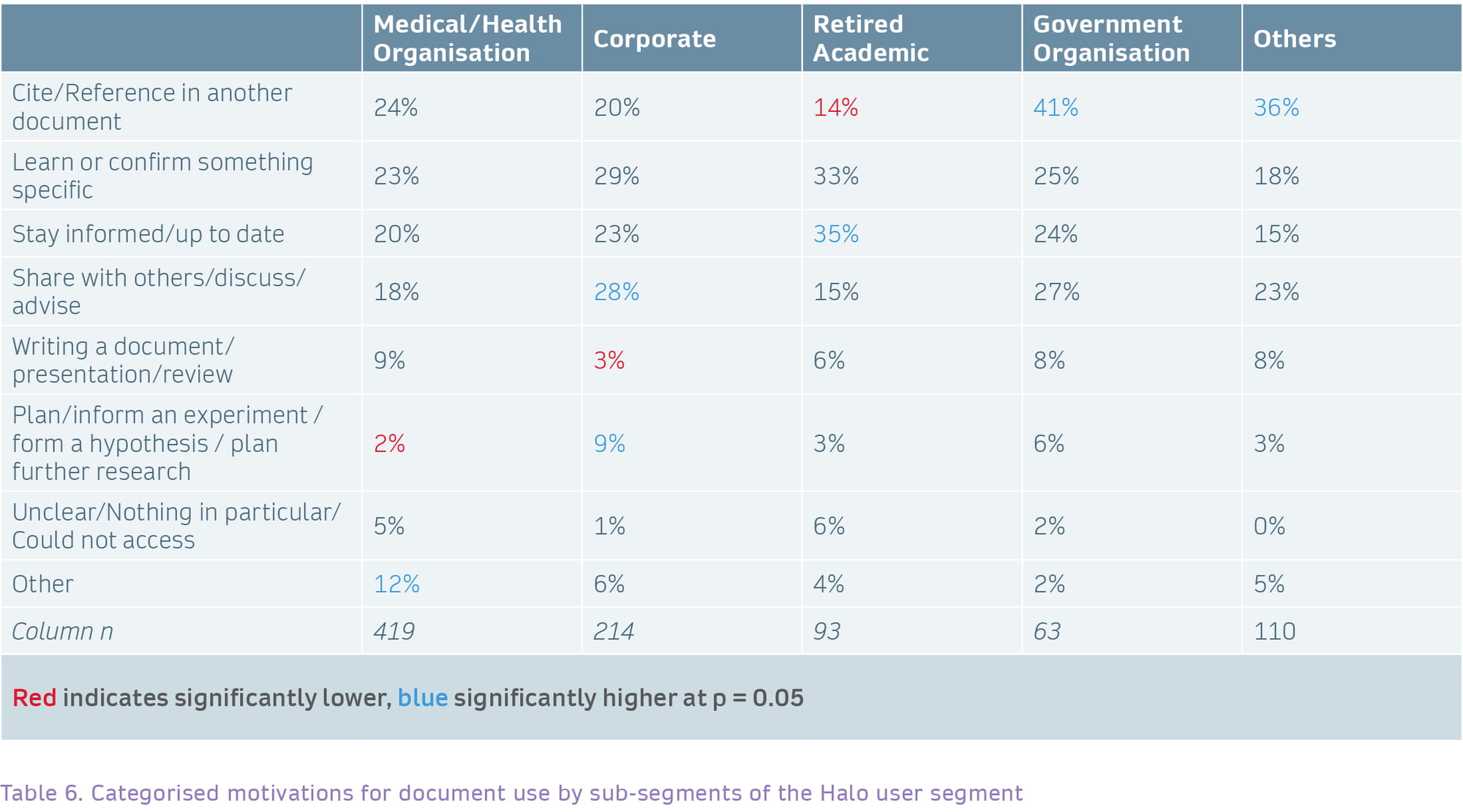
Variance within Halo segment in reported motivations for using research documents
Within the Halo segment, there is further variance in reported motivations for usage. Those at medical organisations were less likely to be using documents to plan research. Corporate users were less likely to be creating documents but more likely to be using documents for discussion or sharing more widely. Finally, those in government organisations were more likely to cite documents.
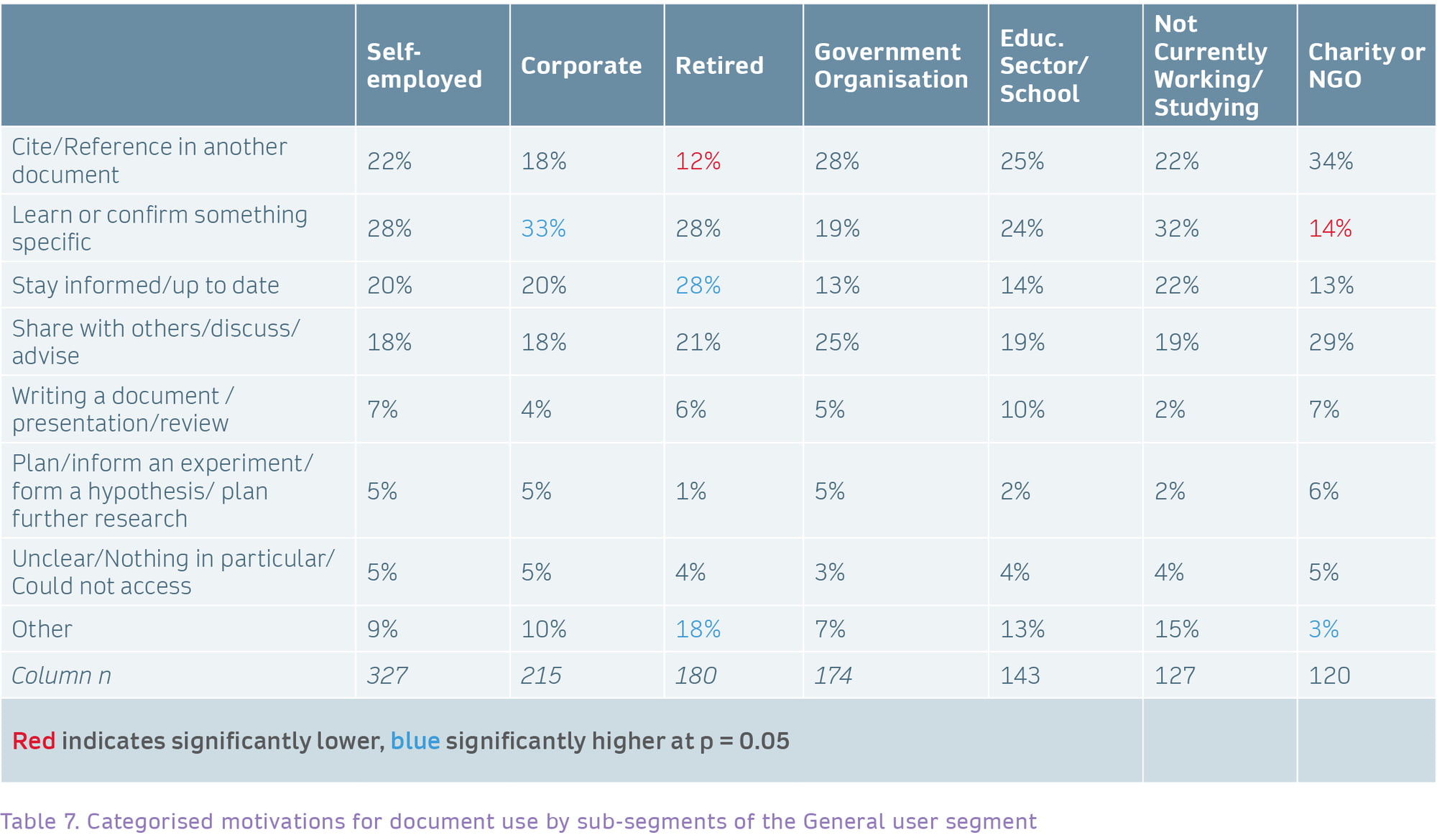
Within the General segment, significant differences were as one would expect. Retired users are less likely to be citing a document (12%), while Corporate users were more likely to be researching something specific (33%).
Sharing of research documents
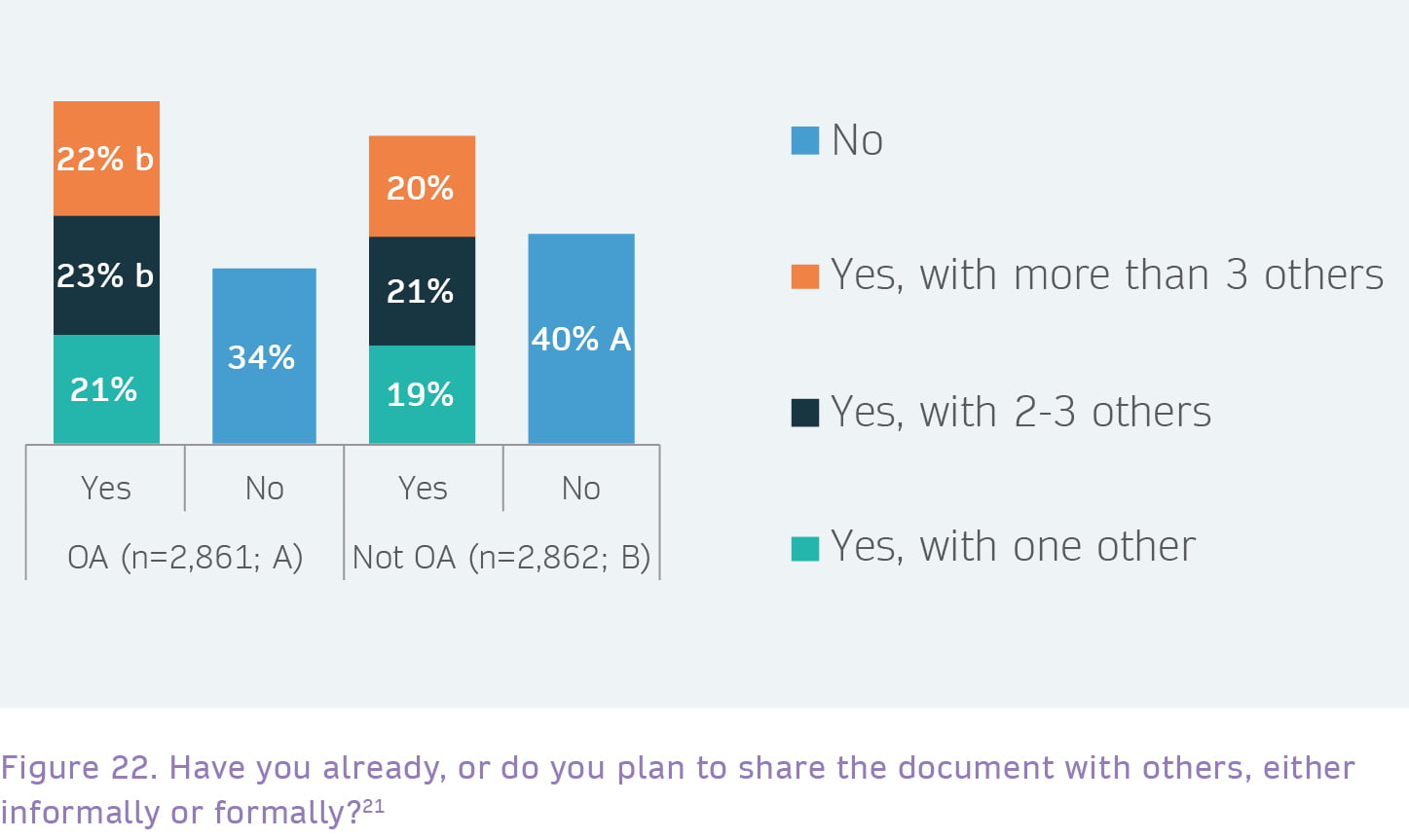
OA content is more likely to be shared with a higher number of people.
Although one of the categorised motivations for using research documents in the previous section was ‘Share with others/discuss/advise’, the survey also asked in more detail about intentions to share.
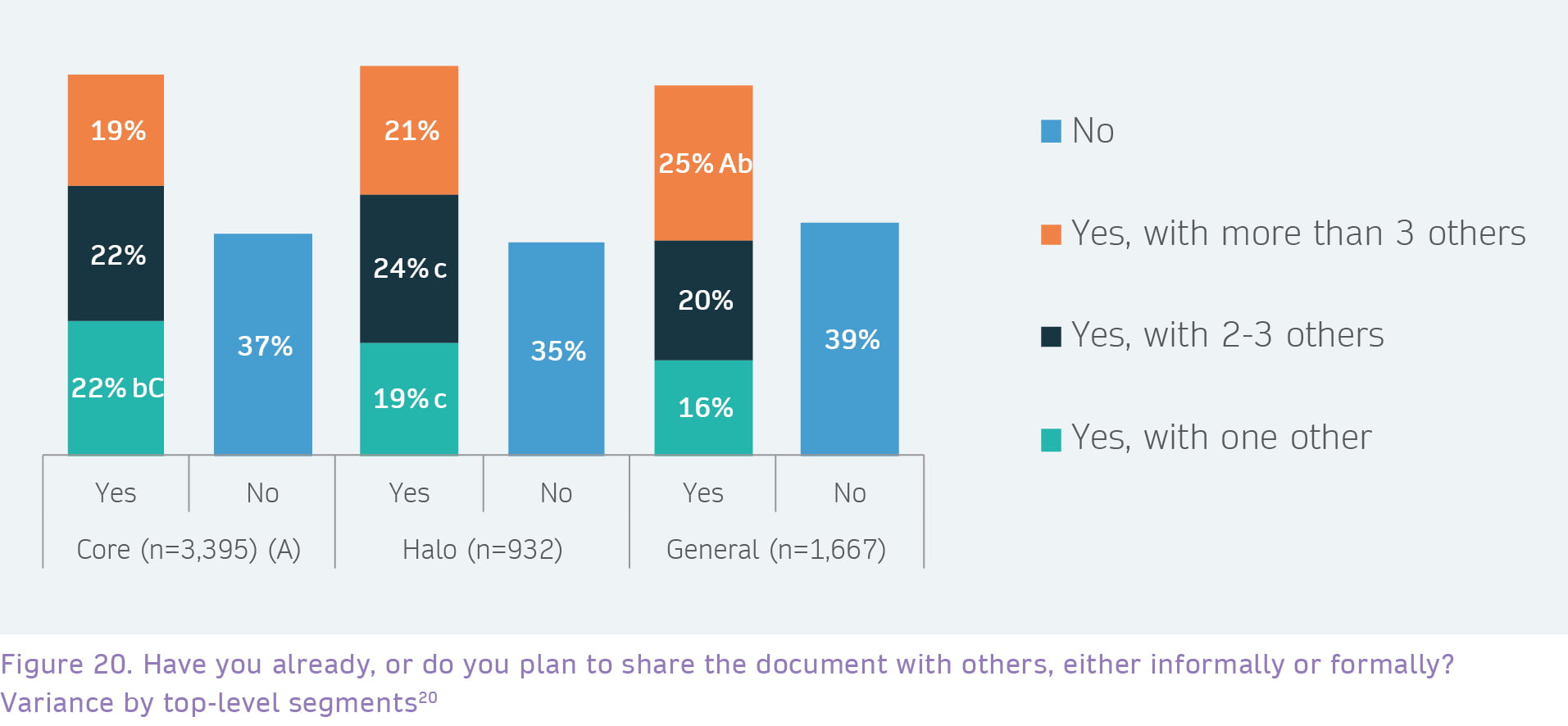
Although respondents from the General segment were overall slightly less likely to say that they would share the research document they read (61% vs 63% and 65%), those that said they would share were significantly more likely to say they would share with more than three other individuals, suggesting that the General segment overall may have a wider potential network and reach.
By contrast, those in the Core segment who said they would share were significantly more likely to report that they would share with just one other. It could be that for many respondents in this group the ‘one other’ would be their supervisor, and this is supported when we find a higher proportion giving this answer were aged under 35 (25% vs net of 22%).
Figure 20: Letters signify where there are statistically significant differences between groups, with a,b,c indicating a difference at p<=0.05 and A,B,C indicating a difference at p<=0.001.
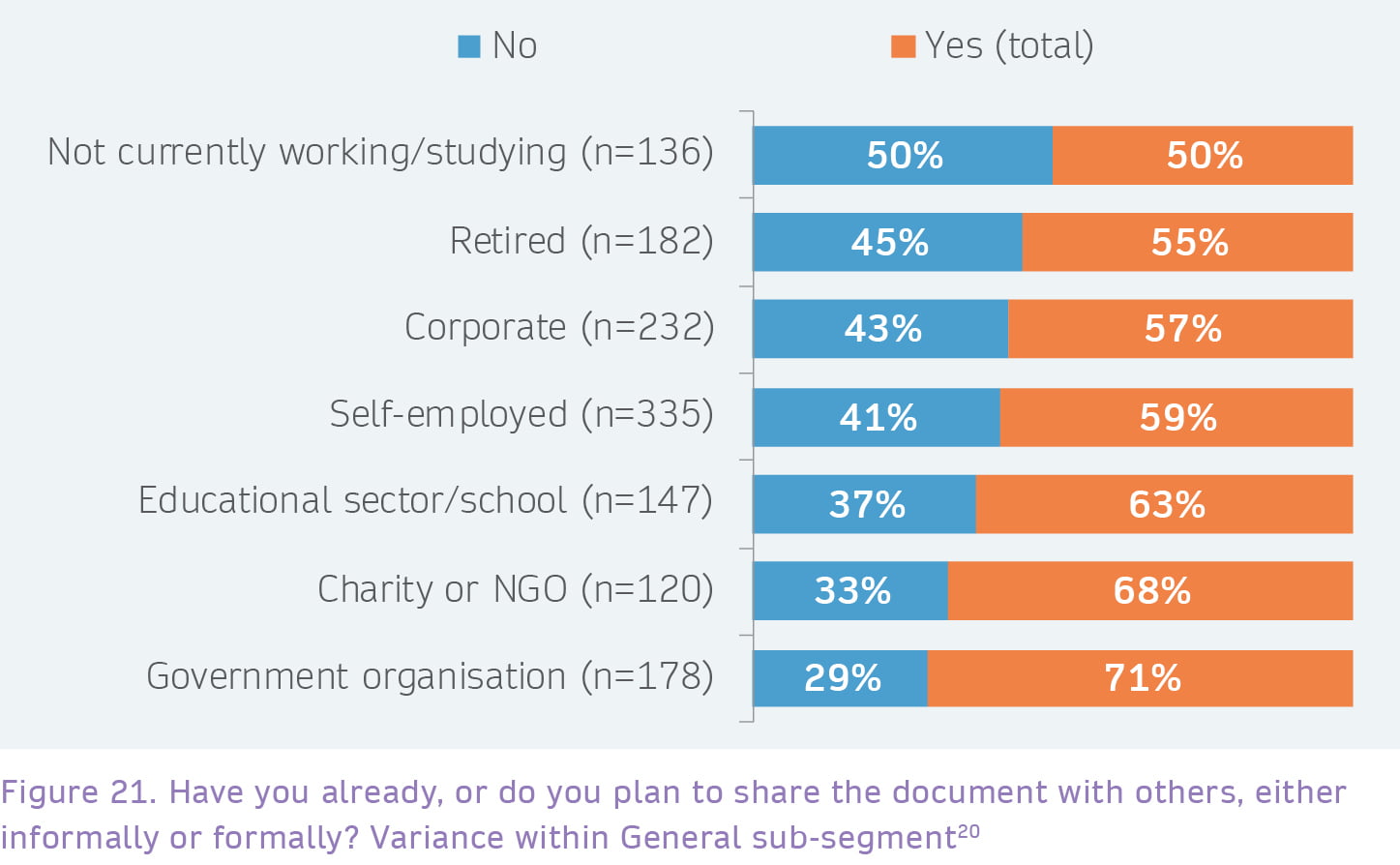
Within the General segment, there is some significant variance in sharing behavior, with very high levels of sharing by those in government organisations, charities and NGOs, but very low levels of sharing by those not working or retired.
Figure 21: Letters signify where there are statistically significant differences between groups, with a,b,c indicating a difference at p<=0.05 and A,B,C indicating a difference at p<=0.001.
Looking at how intention to share varies by OA status of the document, there is a statistically significant increase (at p<=0.001) in likelihood of sharing for users of OA documents. It is not clear whether the intention to share has driven the user to look at an OA article or book chapter, or whether the OA nature of the document means that the user is more likely to share. Regardless, this is a strong indication that OA documents are likely to have a greater penetration and reach.
Furthermore, users who do express an intention to share are more likely to intend to share with a larger number of people: a significantly higher proportion of OA users vs Subscription users (23% vs 21%) say they will share with 2-3 others, and a higher proportion of OA users vs Subscription users (22% vs 20%) say they will share with more than 3 others.